
 Twitte
Twitte
از آنجائیکه نحوهء ارائهء مطلب از همان ابتدا قوی ، کاربردی و همراه با عکس و تصویر مراحل کار بوده ، لذا بعد از این در حین ارائهء مثالهای کاربردی فقط کافیست
از قسمتها و اجزاء تشکیل دهندهء آن نامبرده شود . با اینحال همانطور که دوستان هم اشاره کردند بد نیست یکبار دیگه در هر مرحله توضیحاتی مبنی بر علت
انتخاب اجزاء سیستم ، هدف از آن و در نهایت نتیجهء گرفته شده ، ولو خلاصه قید شود
و اما نظر کلی بنده ... همانطور که میدانید ما انسانها خود دارای مغزی با تعداد بسیار بالای نورونهای مغزی ، چیزی در حدود یکصد میلیارد نورون ، با تریلیونها
سیناپس و ارتباط درونی هستیم که با پردازشی شگرف در امور مختلف زندگی به ما یاری میرسانند که طبق تخمین دانشمندان و محققان فقط توان مصرفی
حدودا 20 وات را بکار میبرند !! شگفت اینکه کارائی محض بستر سیلیکونی مسی پردازشگرهای کامتپیوترهای فعلی را نداشته با دینامیک منحصر به فرد
خود از پس آشوب اطلاعاتی به وجود آمده با مهارتی شگرف برمیایند که خوب اینها همه به یمن میلیونها سال تکامل ، اگر بگوئیم از زمان پیدایش اولین نورونهای
جانوران پرسلولی ، بیش از یک میلیارد سال دگرگونی تدریجی تا کامل شدن پازل بزرگ ، یا در نهایت همان مغز انسان امروزی .
به خاطر همین موضوع است که با وجود پیشرفتهای شگرف در هوش مصنوعی ، هنوز هم جایگزینی احسنت برای آن متصور نیست و در حوزهء تجارت محاسباتی
یا الگوریتمیک هم ، بهترین رویکرد همانا استفاده از عقل منطق انسانی به موازات سیستمهای تجاری مصنوعی ، فرموله شده و نهایتا اتوماسیون شده بوده .
اما هدف از طرح مقدمه بالا ؛ همانطور مستحضرید در ابتدای تاپیک ، چندین بحث در خصوص حل مسئله به کمک شگردهای صرفا آماری توسط استاد جبل عاملی
درگرفت که نشان از پتانسیل بالای روشهای آماری بود . بنده هم چند سالیست به دنبال روشی برای استخراج نزدیکترین (شبیه ترین) آرایش کندلی توسط یک
نرم افزار آماری و ارائهء لیستی از آنها هستم که تا آنجائیکه یادم میاید چند سال قبل یک نمونه کار توسط اکسل از یکی از فرومهای خارجی دیده بودم که نه
بصورت کامل ، به ارائهء لیستی از کندلهای مشابه بعد از استخراج از تاریخچهء قیمت ، در تایم فریم منبع معرفی شده میکرد .
از آنجائیکه نتایجی که بصورت چارت ارائه میشد قابل اسکرول نبودند بعد از مدتی با بی اعتنائی بنده مواجه و رها شد . متاسفانه بدلیل عدم بک آپ گیری و ویروسی
شدن سیستم در پی آن ، فایل آن به همراه فایل DLL (تا آنجائیکه حافظه ام یاری میکند ترکیبی از spreadsheet و اسکریپت برنامه نویسی شده بود) از بین رفت و
بدتر از آن دو سه ماه اخیر هر چه گشتم نمونهء آنرا در اینترنت پیدا نکردم ، فکر کنم یک سایت اندونزیایی بود . به هر حال ..
مزایای چنین سیستم تشخیصی اگر نام سیستم اطلاق بشه ، همانا بکارگیری قدرت تشخیص تریدر (صد میلیارد نورون مقدمهء بالا!!) برای حصول بیشترین نتیجه
به همراه امکان آزادی در پیشرفت و کسب تجربه ، به تصور بنده پتانسیل لازم برای استفاده توسط یک معامله گر حرفه ای رو داره
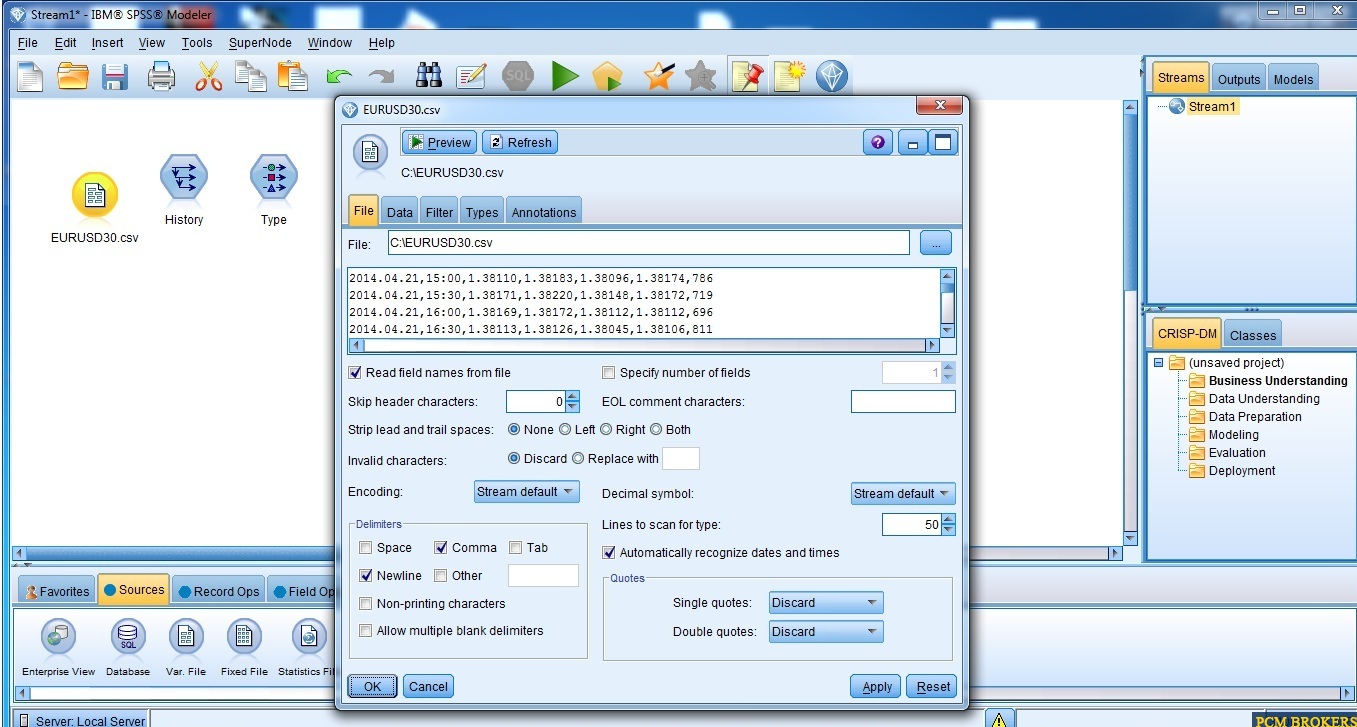
با اینحال بعد از ادامهء تاپیک حالا متوجه شدم که قاعدتا این امر توسط برنامهء SPSS STATISTICS قابل پیاده سازی خواهد بود
علی القاعده در spss modeler امکان پیاده سازی الگوریتمهای پیچیده بصورت ماجولار وجود داره ، و به نظر بنده این کار رو ارزشمند میکنه
منتظر ادامهء کار توسط شما استاد محترم هستیم
از قسمتها و اجزاء تشکیل دهندهء آن نامبرده شود . با اینحال همانطور که دوستان هم اشاره کردند بد نیست یکبار دیگه در هر مرحله توضیحاتی مبنی بر علت
انتخاب اجزاء سیستم ، هدف از آن و در نهایت نتیجهء گرفته شده ، ولو خلاصه قید شود
و اما نظر کلی بنده ... همانطور که میدانید ما انسانها خود دارای مغزی با تعداد بسیار بالای نورونهای مغزی ، چیزی در حدود یکصد میلیارد نورون ، با تریلیونها
سیناپس و ارتباط درونی هستیم که با پردازشی شگرف در امور مختلف زندگی به ما یاری میرسانند که طبق تخمین دانشمندان و محققان فقط توان مصرفی
حدودا 20 وات را بکار میبرند !! شگفت اینکه کارائی محض بستر سیلیکونی مسی پردازشگرهای کامتپیوترهای فعلی را نداشته با دینامیک منحصر به فرد
خود از پس آشوب اطلاعاتی به وجود آمده با مهارتی شگرف برمیایند که خوب اینها همه به یمن میلیونها سال تکامل ، اگر بگوئیم از زمان پیدایش اولین نورونهای
جانوران پرسلولی ، بیش از یک میلیارد سال دگرگونی تدریجی تا کامل شدن پازل بزرگ ، یا در نهایت همان مغز انسان امروزی .
به خاطر همین موضوع است که با وجود پیشرفتهای شگرف در هوش مصنوعی ، هنوز هم جایگزینی احسنت برای آن متصور نیست و در حوزهء تجارت محاسباتی
یا الگوریتمیک هم ، بهترین رویکرد همانا استفاده از عقل منطق انسانی به موازات سیستمهای تجاری مصنوعی ، فرموله شده و نهایتا اتوماسیون شده بوده .
اما هدف از طرح مقدمه بالا ؛ همانطور مستحضرید در ابتدای تاپیک ، چندین بحث در خصوص حل مسئله به کمک شگردهای صرفا آماری توسط استاد جبل عاملی
درگرفت که نشان از پتانسیل بالای روشهای آماری بود . بنده هم چند سالیست به دنبال روشی برای استخراج نزدیکترین (شبیه ترین) آرایش کندلی توسط یک
نرم افزار آماری و ارائهء لیستی از آنها هستم که تا آنجائیکه یادم میاید چند سال قبل یک نمونه کار توسط اکسل از یکی از فرومهای خارجی دیده بودم که نه
بصورت کامل ، به ارائهء لیستی از کندلهای مشابه بعد از استخراج از تاریخچهء قیمت ، در تایم فریم منبع معرفی شده میکرد .
از آنجائیکه نتایجی که بصورت چارت ارائه میشد قابل اسکرول نبودند بعد از مدتی با بی اعتنائی بنده مواجه و رها شد . متاسفانه بدلیل عدم بک آپ گیری و ویروسی
شدن سیستم در پی آن ، فایل آن به همراه فایل DLL (تا آنجائیکه حافظه ام یاری میکند ترکیبی از spreadsheet و اسکریپت برنامه نویسی شده بود) از بین رفت و
بدتر از آن دو سه ماه اخیر هر چه گشتم نمونهء آنرا در اینترنت پیدا نکردم ، فکر کنم یک سایت اندونزیایی بود . به هر حال ..
مزایای چنین سیستم تشخیصی اگر نام سیستم اطلاق بشه ، همانا بکارگیری قدرت تشخیص تریدر (صد میلیارد نورون مقدمهء بالا!!) برای حصول بیشترین نتیجه
به همراه امکان آزادی در پیشرفت و کسب تجربه ، به تصور بنده پتانسیل لازم برای استفاده توسط یک معامله گر حرفه ای رو داره
با اینحال بعد از ادامهء تاپیک حالا متوجه شدم که قاعدتا این امر توسط برنامهء SPSS STATISTICS قابل پیاده سازی خواهد بود
علی القاعده در spss modeler امکان پیاده سازی الگوریتمهای پیچیده بصورت ماجولار وجود داره ، و به نظر بنده این کار رو ارزشمند میکنه
منتظر ادامهء کار توسط شما استاد محترم هستیم



 به گزارش روز چهارشنبه ایرنا از سنا، محمد اسلام تنها در ساعت تفریح خود در مدرسه و با استفاده از اینترنت توانست یکی از برجسته ترین سهامداران وال استریت شود.
به گزارش روز چهارشنبه ایرنا از سنا، محمد اسلام تنها در ساعت تفریح خود در مدرسه و با استفاده از اینترنت توانست یکی از برجسته ترین سهامداران وال استریت شود.
نظر